Pandas 3.0: A Paradigm Shift in Data Processing with PyArrow Integration
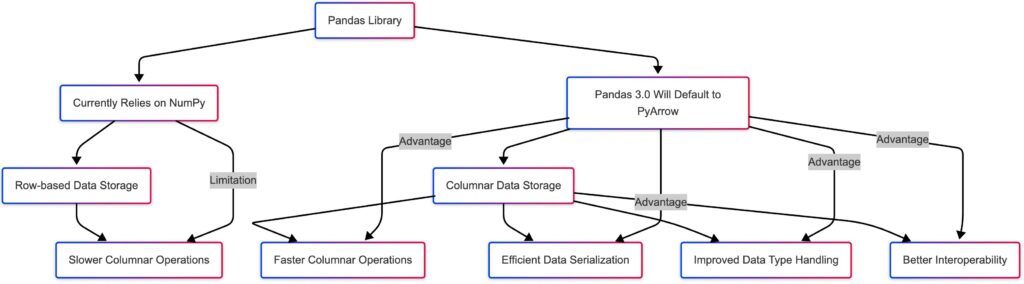
The Python ecosystem is on the cusp of a significant evolution in data manipulation and analysis with the upcoming release of Pandas 3.0. This version promises a substantial performance boost by fundamentally changing its underlying engine for columnar data. The long-standing reliance on NumPy as the default will be replaced by Apache PyArrow, a move that is expected to drastically improve the speed and efficiency of data loading and processing, particularly for columnar datasets. This transition, while already offering optional support in recent Pandas versions, marks a pivotal moment in the library’s history, addressing limitations inherent in its foundational dependency and paving the way for more efficient data workflows.
The Historical Context: Pandas and NumPy
To understand the significance of this shift, it’s crucial to appreciate the historical relationship between Pandas and NumPy. Created by Wes McKinney in 2008, Pandas rapidly became the go-to library for data analysis in Python. Its core data structures, the Series (for one-dimensional data) and the DataFrame (for tabular data), were built as high-level abstractions over NumPy arrays. This design leveraged NumPy’s efficient C implementations and vectorized operations, enabling Pandas to perform data manipulations much faster than would be possible with pure Python.
For example, consider a simple operation of adding two Series:
Example 1: Adding Pandas Series (underlying NumPy)
In this seemingly straightforward operation, Pandas relies on NumPy’s optimized routines for the actual element-wise addition, providing a significant performance advantage over iterating through Python lists. This fundamental architecture has served the data science community well for over a decade.
However, as data volumes grew and the complexity of data formats increased, the limitations of NumPy in handling certain modern data challenges became more apparent. While NumPy excels at numerical computations on homogeneous arrays, it struggles with:
- Columnar Data Processing: NumPy’s row-major storage makes operations on columns less efficient as it requires traversing through non-contiguous memory locations.
- Data Types: Handling complex or nested data types, as well as efficient representation of strings and dates, is not NumPy’s forte.
- Missing Data: While Pandas provides mechanisms for handling missing data (NaN), the underlying NumPy representation can sometimes lead to inefficiencies.
- Scalability and Modern Data Paradigms: NumPy was not designed with modern data concerns like streaming data or distributed computing in mind.
- Threading: Its Global Interpreter Lock (GIL) restricts true multi-threading for CPU-bound tasks.
The introduction of PyArrow as the default engine in Pandas 3.0 directly addresses these limitations.
The PyArrow Advantage: A Columnar Revolution
Apache PyArrow is a cross-language development platform for in-memory data analytics. Its columnar memory format is specifically designed for efficient data processing. Unlike row-based formats where data for a single row is stored contiguously, columnar formats store data for each column together in memory. This offers several key advantages:
- Faster Columnar Operations: When performing operations on specific columns (a very common task in data analysis), only the relevant column data needs to be accessed, leading to significant speedups, especially for large datasets.
- Efficient Data Serialization and Deserialization: PyArrow provides optimized mechanisms for reading and writing data in various formats (e.g., Parquet, Feather) with minimal overhead.
- Improved Handling of Data Types: PyArrow supports a rich set of data types, including efficient representations for strings, dates, timestamps with timezones, and nested data structures.
- Compression and Encoding: PyArrow integrates compression and encoding techniques that can significantly reduce memory usage and I/O time.
- Interoperability: Being a cross-language platform, PyArrow facilitates seamless data exchange between Python and other languages like Java, C++, and R.
- Integration with Big Data Technologies: PyArrow is a foundational component of many big data processing frameworks like Apache Spark and Dask, making Pandas 3.0 better positioned for integration with these ecosystems.
Reuven Lerner’s observation at PyCon 2025, stating that PyArrow is “10 times faster,” while potentially an anecdotal maximum, highlights the significant performance gains users can expect in many scenarios, particularly when dealing with large columnar datasets.
Example 2: Reading a CSV file with PyArrow (current Pandas)
In this example, even in current versions of Pandas, specifying engine='pyarrow' during data loading can result in noticeable speed improvements, especially for large files with many columns. In Pandas 3.0, this behavior will be the default.
Furthermore, the change to pyarrow.string as the default type for string data will address some performance bottlenecks associated with NumPy’s object dtype used for strings in Pandas. PyArrow’s native string type is more memory-efficient and allows for vectorized string operations.
Implications and the Future of Pandas
The decision to make PyArrow the default engine in Pandas 3.0 is a strategic move that will have far-reaching implications for the Python data science ecosystem.
Performance Gains
The most immediate impact will be on performance. Operations involving data loading, filtering, grouping, and aggregation on columnar data are expected to be significantly faster. This will be particularly beneficial for users working with large datasets and those who frequently perform analytical queries on specific columns.
Enhanced Data Handling Capabilities
Pandas 3.0 will be better equipped to handle modern data formats and complex data types. The improved support for dates, timestamps with timezones, and nested data will make Pandas more versatile for a wider range of data analysis tasks.
Seamless Integration with the Big Data Ecosystem
The stronger integration with PyArrow will facilitate smoother interoperability between Pandas and other big data tools. This will allow users to leverage the strengths of Pandas for data exploration and manipulation on data processed by frameworks like Spark and Dask more efficiently.
Migration and Compatibility
While the transition to PyArrow as the default engine is a significant change, the Pandas development team is likely to prioritize backward compatibility to minimize disruption for existing users. However, users with code that relies heavily on the specific behavior of NumPy arrays within Pandas might encounter some compatibility issues and may need to make adjustments. The fact that PyArrow support has been available since Pandas 2.0 provides a good runway for users to test and adapt their workflows. The requirement of PyArrow as a dependency will also be a new factor in environment management.
Release Timeline
As noted in the initial information, the release of Pandas 3.0 has faced delays. The original target of April 2024 has passed, and as of the latest information, a concrete release date is still pending. The most recent release, version 2.2.3 in September, indicates ongoing development and refinement. The community eagerly awaits the official announcement of the 3.0 release, recognizing its potential to usher in a new era of performance and efficiency for Pandas users.
In Summary
The integration of PyArrow as the default engine in Pandas 3.0 represents a significant step forward for the library. By embracing a columnar memory format, Pandas is poised to overcome some of the performance limitations inherent in its NumPy-based architecture and better cater to the demands of modern data analysis. While the exact release date remains uncertain, the eventual arrival of Pandas 3.0 promises a faster, more efficient, and more versatile data manipulation experience for the vast community of Python data scientists and analysts. This transition underscores the ongoing evolution of Pandas as a vital tool in the data science landscape, ensuring its continued relevance and performance in the face of ever-increasing data volumes and complexity.
